What a Polygenic Risk Score Can and Can’t Tell You
Scientists have made great strides in predicting the genetic risk of common diseases. Figuring out what to do with that information may be just as hard.
- 10 min read
- Feature
As a cardiologist, Pradeep Natarajan, MMSc ’15, knows that high blood pressure, smoking, and high cholesterol raise a patient’s risk of developing coronary artery disease.
But Natarajan, an HMS associate professor of medicine and the director of preventive cardiology at Massachusetts General Hospital, also knows that there are many people at risk who don’t have such obvious indications — young, seemingly healthy people oblivious to the plaque accumulating in their arteries. He likely won’t encounter those patients until many years later. “Heart disease is the leading killer in the U.S., and the process does not start overnight,” Natarajan says. “Often it starts quite early, but our clinical tools recognize high-risk individuals too late, missing opportunities to prevent premature heart attacks.”
Heart disease can be tough to predict, because like many common conditions, it stems from a blend of genes and environment that varies from person to person. One patient might have no family history or genetic predisposition but adopt habits that elevate risk. Another could lead a relatively healthy lifestyle but still develop the disease due to genetic predisposition. The latter patient is less likely to raise red flags during routine-care visits and could miss out on opportunities for testing and monitoring.
But what if doctors could pinpoint exactly which patients have an elevated genetic risk of heart disease and other common conditions much earlier? Natarajan is among a group of scientists refining new tools that can do exactly this. These “polygenic risk score” tests comb through a person’s DNA to calculate genetic predisposition not only to heart disease but also to many other conditions, such as type 2 diabetes, Alzheimer’s disease, and common cancers. And as these tests become more reliable, they raise key questions about how to use them: Should we all know our polygenic risk scores? And if so, how do we make sense of what the scores tell us — and what they don’t?
What’s written in the code
When the initial sequencing of the human genome was completed in the early 2000s, it was a big deal. “Humankind is on the verge of gaining immense, new power to heal,” said President Bill Clinton at a 2000 event announcing the genome’s first draft. “Doctors increasingly will be able to cure illnesses like Alzheimer’s, Parkinson’s, diabetes, and cancer by attacking their genetic roots.”
It was an optimistic idea: Armed with a map of the 3 billion chemical base pairs comprising human DNA, scientists would finally identify genetic mutations causing the most common diseases, paving the way for targeted treatments.
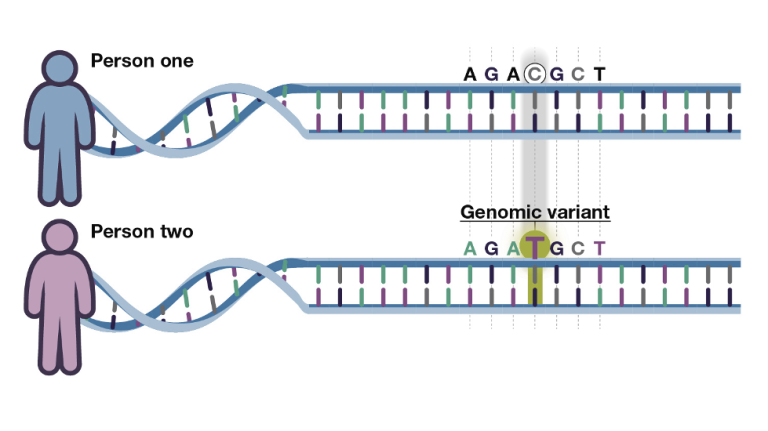
Scientists had previously discovered variations in single genes with direct links to disease, called “monogenic” variants, like the mutations that cause cystic fibrosis or Huntington’s disease. And sure enough, they did end up finding many more. The hope was that they’d do the same for more widespread conditions — heart disease, diabetes, and common cancers, for example. Instead, they realized, these conditions tend to be “polygenic,” shaped by the cumulative effects of many thousands of tiny changes in the genetic code that vary between individuals.
To really understand the relationship between genes and most diseases, they’d need to parse the subtle effects of each individual genetic variant. That’s the first step in developing a polygenic risk score. Researchers compare genetic information from two groups of people, some who developed a given disease and some who didn’t. They look at the frequency of certain variants among the groups to calculate how much each one correlates with developing the disease. Every correlated variant gets a “weight” reflecting whether it’s linked to the disease or protective against it. Add up the weighted contributions of all relevant genetic variants a person carries and you end up with their polygenic risk.
“You’re able to look at these computational patterns and put everybody on a bell curve,” says Robert Green, an HMS professor of medicine and director of the Preventive Genomics Clinic at Brigham and Women’s Hospital. Most people fall somewhere in the middle, but as you move right or left, “you can determine the people who are in the highest and lowest categories for polygenic risk.”

Where a person lands on that curve, Green explains, determines their polygenic risk for a given disease. Sometimes it’s expressed as a percentile; a person in the 97th percentile on the type 2 diabetes curve has a genetic risk of diabetes higher than 97 percent of the population. Sometimes it’s interpreted in categories: you draw a line to indicate where on the curve a risk level becomes double or triple the average and classify everyone to its right as high risk.
Evening the score
The first versions of these scores in the early 2000s were based on a handful of genetic markers and studies involving a few thousand people, most of whom were of European ancestry. The scores could identify modest levels of risk but weren’t powerful enough to distinguish the highest-risk individuals, and they were even less predictive for people of non-European backgrounds. But in recent years, access to genetic data from study participants has exploded. More genetic variants have been explored as computational methods became more advanced. Today’s scores draw data from millions of markers among samples from millions of people.
As a result, the scores have improved. In a 2018 study, Natarajan and other HMS researchers at Mass General developed polygenic risk scores for coronary artery disease, atrial fibrillation, type 2 diabetes, inflammatory bowel disease, and breast cancer that could be just as powerful at predicting disease as the presence of certain monogenic mutations. Natarajan and cardiologist Aniruddh Patel, an HMS instructor in medicine at Mass General, have more recently been tackling the ongoing issue of bias in the scores by including data from more diverse ancestry groups. In 2023 they developed a risk score for coronary artery disease that outperformed all others published to date for participants of European, Hispanic, South Asian, and African ancestries.
Improved scores are revealing just how many people have a genetic predisposition to common disease. “It turns out there’s actually a large number of people that you can find at very high risk,” Natarajan says. His research indicates that one out of every five individuals has a genetic risk of coronary artery disease that is three times higher than average. In Green’s Preventive Genomics Clinic — which offers polygenic screening for type 2 diabetes, Alzheimer’s disease, coronary artery disease, and breast or prostate cancer as part of a broader package of genomic tests — nearly a third of people are found to have double the average risk of at least one of those conditions.
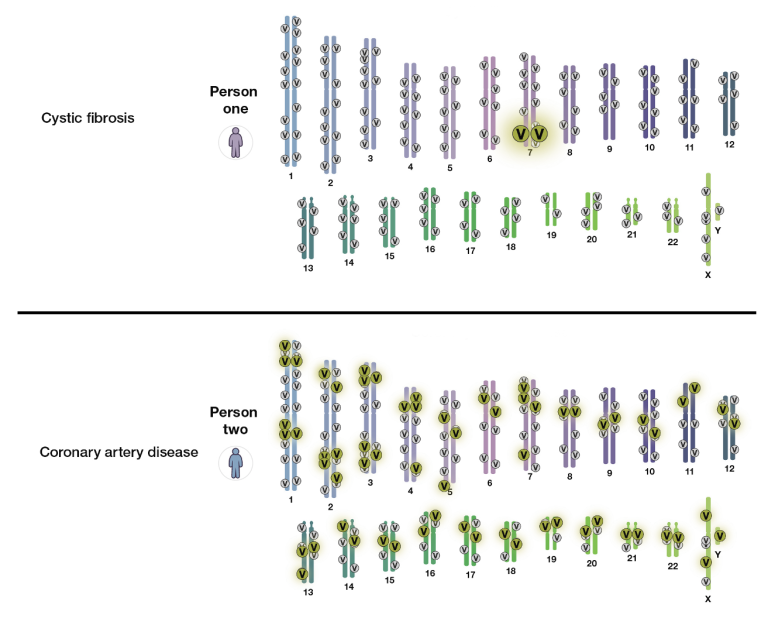
That’s a much higher proportion of people than those born with a single gene mutation linked to disease. “Maybe 2 or 3 percent of a population has a pathogenic variant in a monogenic disease,” says Jason Vassy, an HMS associate professor of medicine based at the VA Boston Healthcare System. “So if high-risk polygenic scores turn out to be clinically useful, it will have huge implications for population health.”
DNA isn’t destiny
Polygenic screening is flipping the paradigm of genetic testing on its head. Tests for monogenic mutations have been around for decades and are typically used when patients present with a problem and a physician needs to find out what’s wrong. But polygenic risk is about prevention. “You’d be doing the genetic testing up front as a screening measure in a healthy population, just like you’d check cholesterol or blood pressure,” says Patel.
Patel is quick to emphasize, though, that it’s easy to get caught up in the allure of the numbers and forget that genetics are just one part of the equation. Even if you’re in the 99th percentile of polygenic risk on the curve, this does not always translate to the 99th percentile of actual disease risk; you’re in the 99th percentile of the known genetic component of risk. And according to Patel’s research, even if you take the people in the very top percentile of polygenic risk for coronary artery disease, only about 16 percent will actually develop the disease by middle age. Lifestyle, environment, health care access, and sheer luck are powerful forces, too.
“Statistically and mathematically speaking, the score is very good in terms of differentiating risk,” Patel says. “But to go up to somebody in the general population and say, ‘You have a threefold risk,’ that’s a little terrifying. Even being in the top percentile is not condemnation. At the patient level, it’s not a done deal.”
That’s one reason polygenic risk scores are so difficult to interpret. “Communicating what this is, and what it isn’t, is actually quite challenging,” says Green. “Do I just say ‘Yes, you have an elevated polygenic risk score of atrial fibrillation,’ or do I report this in some sort of fancy way with bells and whistles and heatmaps? That’s the most interesting part of this, because how you describe the findings and show the information to doctors and patients often dictates what they do next.”
The more you know?
What doctors and patients ultimately do with the information is what matters most. Would understanding a person’s genetic risk help prevent the development or worsening of disease, or would it lead to a slew of unnecessary tests and interventions?
Putting a patient at risk of atrial fibrillation on anticoagulation therapy, for example, comes with an additional risk of major bleeding. Unnecessary colonoscopies and biopsies cost time and money. But for heart disease, Patel says there aren’t many downsides to knowing a person is at higher risk because preventive treatments are fairly safe. “One thing that polygenic risk scores help with is motivating lifestyle and behavioral changes,” he says. “You’re always told that you should exercise, you should not smoke, you should eat well. But I think that if you know there’s this extra risk, that may motivate you.”
Some research does support this notion. A 2023 meta-analysis found that patients receiving high-risk polygenic scores for various diseases were more likely to exercise, take vitamins and supplements, or even wear more sunscreen — although a few of the studies it reviewed had found no link between receiving scores and changing behaviors.
It also matters how physicians react to the scores. In 2014, Green worked with cardiologist Iftikhar Kullo and colleagues at Mayo Clinic on one of the few prospective studies to explore the benefits of knowing about a genetic predisposition to heart disease. They found that participants who received high polygenic risk results for heart disease were — in consultation with their doctors — more likely to begin taking statins than those who didn’t receive their results, resulting in lower cholesterol levels. A ten-year follow-up study, released last month and currently under peer review, found that participants who had received their risk scores also ended up experiencing fewer cardiovascular events over the next decade.
While such evidence is promising, there aren’t yet solid guidelines for physicians about how to act on the tests. In a clinic like Green’s at Brigham and Women’s, patients benefit from the help of genetics experts. But since polygenic testing isn’t typically covered by insurance, those patients need to pay out of pocket or participate in research studies. Millions of other people are getting tested through private companies like 23andMe and then bringing the test results to their primary care providers, many of whom haven’t had training on how to act on the information.
“When I was in medical school, I didn’t know what a polygenic risk score was, and that wasn’t that long ago,” Patel says. “We need to be able to tell the primary care physician how to interpret and deal with this information, because they’re the hub of preventive patient care.”

A primary care physician, Vassy is one of the few researchers investigating whether polygenic risk scores could be useful in primary care. In one prospective trial he’s leading, participants were randomly placed in two groups. Half received a copy of their polygenic risk test results for six common diseases at baseline (their primary care providers were also given the scores). The other half didn’t receive their scores. After two years, Vassy and colleagues will assess whether getting the polygenic test results led to a higher likelihood of being diagnosed with disease — which, Vassy says, can lead to earlier treatment and avoid more advanced cases. In another study, they’re examining whether polygenic risk scores can help prioritize who should be screened for prostate cancer, a decision that has vague guidelines. Men with a high genetic risk might be better candidates for screening, whereas those at low risk would be more likely to undergo unnecessary biopsies if screened.
Vassy’s studies will also evaluate how giving primary care providers and patients educational materials to aid with decision-making and presenting results in simple categories like “high risk” and “low risk” could help in the time-constrained primary care setting. “There’s an appetite and interest in figuring out how, if at all, it could improve patient outcomes,” Vassy says.
The long game
Vassy and colleagues are studying older adults and focusing on outcomes they can measure in a two-year timespan. Their study won’t reveal longer-term outcomes, though, like whether the patients who receive polygenic risk scores ultimately live longer. Since a person’s genetic risk stays constant throughout their lifetime, in theory anyone could find out their polygenic risk as early as birth or even conception. If a young patient and their doctor knew about an elevated genetic risk of diabetes, for example, would that patient be less likely to develop the disease by the time they’re fifty? Would they be less likely to die by age seventy?
Answering these questions would take decades. And with the average NIH grant lasting around three to five years, the U.S. research system isn’t structured to do so. Nor is the employer-funded U.S. health insurance system, says Green, which is primarily focused on short-term outcomes.
Prevention can be a hard sell for patients, too. If a cardiac patient feels fine to begin with and takes a statin, says Natarajan, it won’t make them feel any better. And if they never get heart disease, they’ll never really know whether to thank the statin or not. “They have to understand why I would recommend a type of preventive therapy, whether there is sufficient risk, and what the science behind it is,” he says. “Only then does it really make sense.”
Green hopes that continued research into genetic testing — not only polygenic risk but also monogenic and other types of screening — will ultimately yield scientific evidence that there are benefits to reducing uncertainty by quantifying risk. And, he adds, the fact that the scores come with inherent uncertainties should not negate their usefulness.
“If you think about it, every interaction in medicine is a probabilistic interaction,” says Green. “If you come into the emergency room with chest pain, it increases the probability that you’re suffering a heart attack. But it’s not 100 percent. It might be epigastric pain. This is exactly the same idea, but we’ve not chosen to see it the same way.”
“If you are in the tail end of the curve for a polygenic risk score, you are absolutely at a higher risk for that condition,” he adds. “And we wish to act on that. Really, that’s what medicine is all about.”
Molly McDonough is the associate editor of Harvard Medicine.
Images: Maya Rucinski-Szwec (tarot cards); courtesy of the National Human Genome Research Institute (infographics); courtesy of Robert Green (Green)
Continued funding uncertainty jeopardizes promising HMS research advances.